Last month Nvidia released a new realtime stereo depth estimation model (Links to paper & github below)
In my testing I’ve found that it’s results are superior to those provided by the model in the ZED SDK (Neural & Neural Plus) using the ZED X Camera (Wide FOV, Polarizer)
Are there plans to either integrate this new stereo depth estimation model into the ZED SDK or train your own new models based on their architecture?
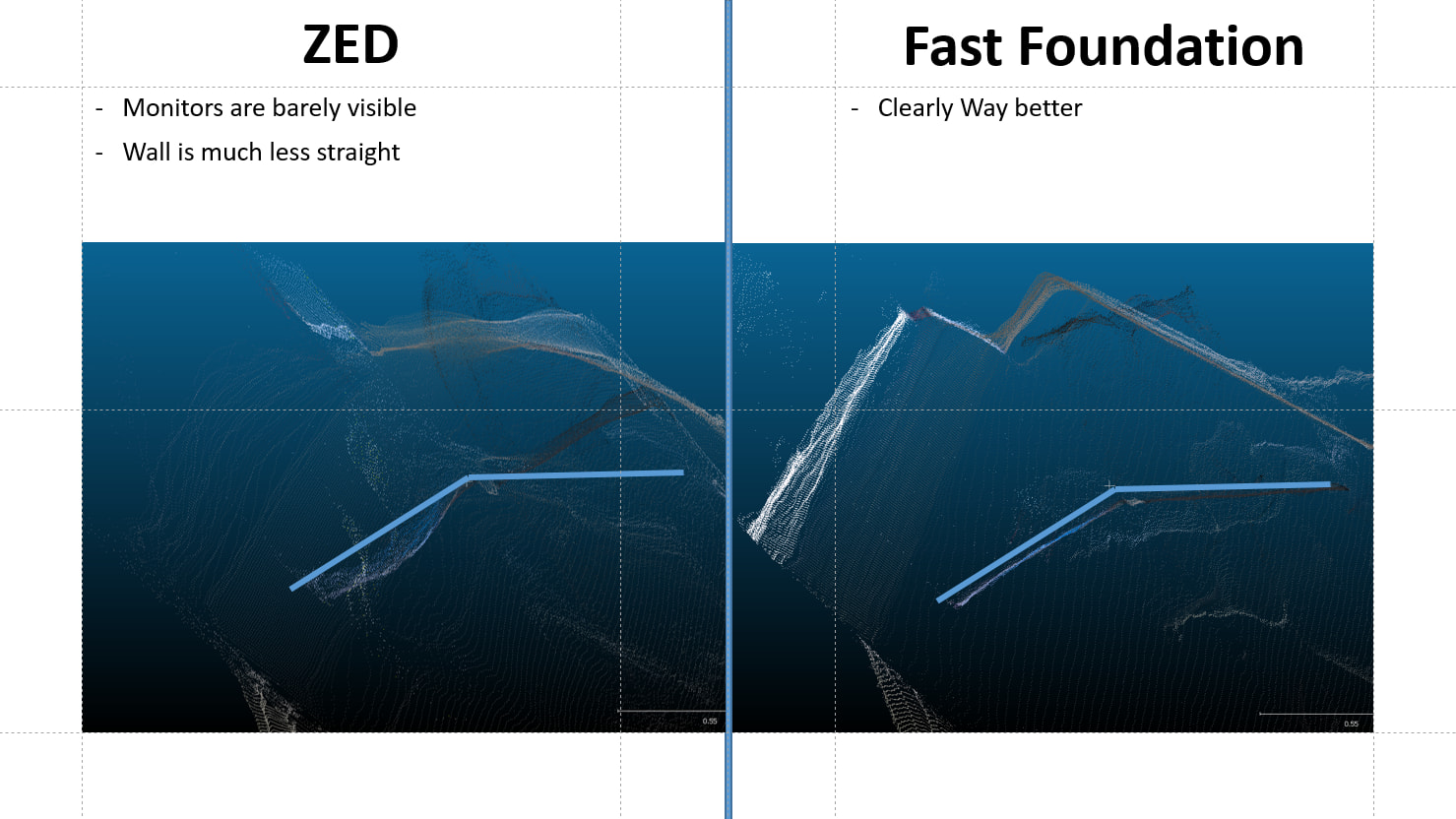
Here’s some examples of how the new Nvidia model is doing a better job. There are some other samples I’ve compiled for showing to my coworkers, however the source image is from within my office and has some sensitive material. So here are a couple samples that I’m comfortable sharing. In almost all aspects I find that the nvidia model captures the geometry of the office better.
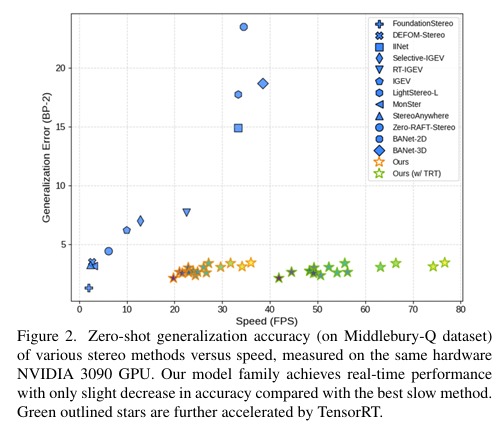
Nvidia also has some samples comparing their model to the ZED model.
However, this is their FoundationStereo model which was released early last year and not real-time. Their Fast-Foundation Stereo site does not have direct comparisons against the ZED Camera, however it’s quality is claimed (And to my eye is) to be very similar to their Foundation Stereo model
Here is a portion of the source image that was used to create the PCD.
Currently I’m doing the inference on my cpu on a fairly powerful desktop. I’m going to be getting it running on a Jetson AGX Orin in the future to test how quickly it runs with the tensorrt engine.
Nvidia measured the speed using a 3090 which I’m guessing inferences ~3-4 times faster than the AGX Orin so I doubt it can get 30 FPS. However I have no idea how much they quantized their model and what not.
Real-time processing is definitely my biggest concern; it’s always about finding the right balance and meeting the task requirements.
Please feel free to share your Jetson performance results. If you have the opportunity to run additional tests, we’d be happy to discuss them.
In the meantime, our R&D team has confirmed they’re working on these new algorithms, as well as other promising AI methods for depth processing, and you can be sure the ZED SDK will offer improved depth AI performance with each release… starting with the new v5.3, which will be announced soon.
On the AGX Orin 64GB I have a version that runs using TensorRT at 640x384 which is roughly 1/3 of the 1920x1200 resolution, but you need to drop a few pixels vertically since the resolution needs to be divisible by 32. The max disparity was set to 128 and 4 validation iterations.
The resulting point cloud is not as good as the full resolution one, however not significantly worse. I get 13 FPS out of it. I can’t share the PCD I was testing with, but it’s more consistent than the one provided by the ZED SDK and can see about 7 - 12 meters further. Though the resolution is obviously significantly lower so the objects at that range, in this case me, had only about 40 points.
For my current use case I’m definitely interested in a higher quality point cloud at the cost frame rate and resolution. I do think the Fast-Foundation Stereo is not quite as fast as I need it to be, but the point cloud quality and the extra range is very nice. If in future Stereolabs can provide a model closer to the level of quality of Fast-Foundation Stereo with okay performance (~15 FPS) that would be good for my use-case.