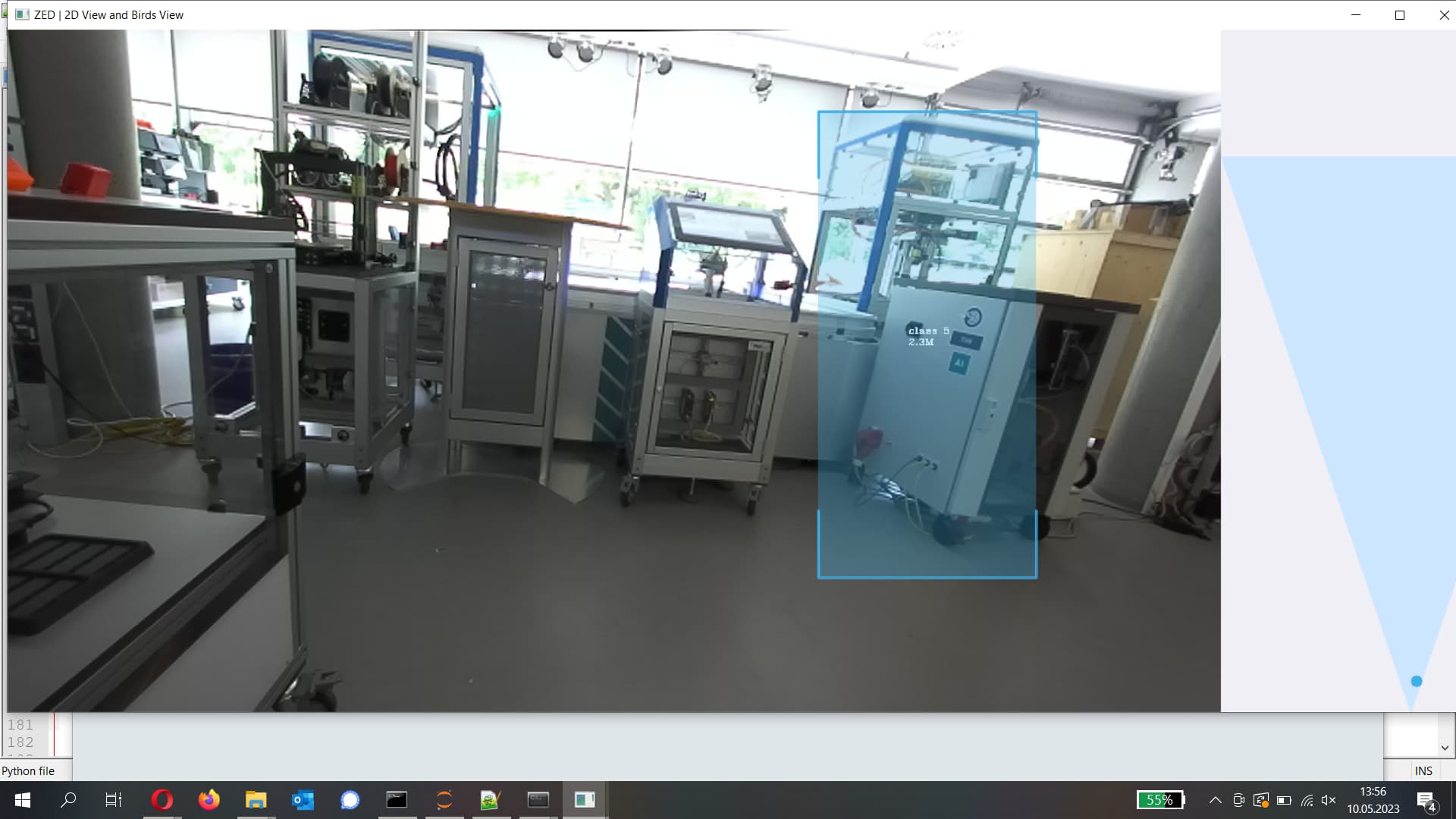
For the inference, I’m running this prompt: python3 custom_object_detection_v2.py --weights ...\weights\best.pt --img_size 640
custom_object_detection_v2.py is this code, which you provided.
If I run the inference via the prompt the yolo documentation provides (python3 detect.py --weights ...\weights\best.pt --source 0) I get the following results:
You can see the images of both cameras of the ZED 2 camera and all the right classifications.
So, I have the following questions:
What am I missing, that I get excellent results when running the prompt of the yolo documentation and nearly no object detections when running the same model on the ZED script?
Where do I have to change the class names, that they show up on the bbox of the inference?
How is the parameter called exactly which I need to change?
I found this in the documentation and added obj_param.filtering_mode = None line to my script at this position:
Thanks, that already helped a little bit. Are there further options to get better results on the prediction from the ZED camera?
The amount of detected objects and the precision is still not comparable to the results of the yolo inference.
To elaborate on what I tried so far:
I tried setting the OBJECT_FILTERING_MODE to NONE
I set the detection confidence threshold in ObjectDetectionRuntime to 10: