I’m attempting to use two zed x minis on a single Orin NX (ROS 1).
To do this, I’m opening camera streams using local video streaming module on the Orin and then pointing two zed nodes (also on the Orin) to the streams using their stream ip addresses, one node per stream.
I then have another machine that also either uses gstreamer, gscam or the video streaming module to ingest the streams produced on the Orin.
My issue is that, at least one of the zed nodes seems to consistently die after a minute or two of operation.
I’ve reduced the depth modes of both cameras to PERFORMANCE and reduced the resolution/bitrate of one camera to SVGA/5000 while keeping the other at HD1200/7000. However, this hasn’t helped.
Should the Orin NX be able to handle this configuration?
If so, what settings are best?
Additionally, am I correct in thinking that the settings (e.g. resolution, bitrate, etc.) used in the streaming module to open the streams are what actually get used by the subsequent streams’ subscribers such as the zed nodes and video module subscribers on other machines, even though they may list differing values when they are spun up (I’ve been leaving them in default values…)? Or do the stream subscribers alter the configuration of streams?
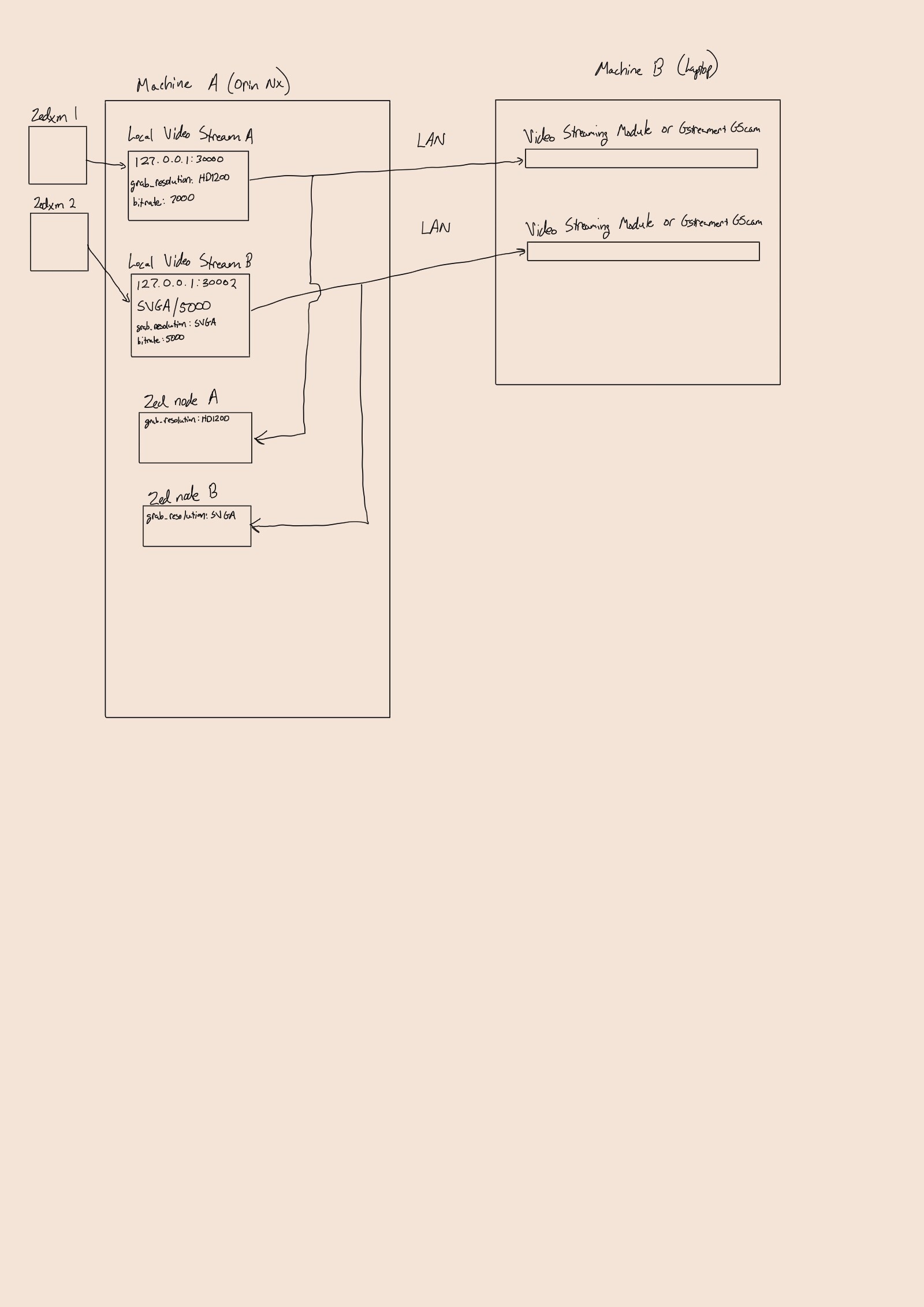
Can you draw a scheme of this configuration to make it more clear?
What’s the error that you get when a node crashes?
What power mode are you using? Did you monitor CPU, GPU, and the overall temperature of the system?
The stream sender sets the resolution and framerate, but the ROS nodes has parameters to subsample the output resolution to limit the required bandwidth:
I put the parameters used for the streams in the drawing. Other than what is shown, I use defaults.
This is an example error:
================================================================================REQUIRED process [warpauv_2/cameras/forward/zed_node-2] has died!
process has died [pid 14395, exit code -6, cmd /home/warp/warp_ws/devel/lib/zed_wrapper/zed_wrapper_node __name:=zed_node __log:=/home/warp/.ros/log/88b4d078-16d6-11ef-8214-b3c3ab1f522c/warpauv_2-cameras-forward
-zed_node-2.log].
log file: /home/warp/.ros/log/88b4d078-16d6-11ef-8214-b3c3ab1f522c/warpauv_2-cameras-forward-zed_node-2*.log
Initiating shutdown!
The power mode is MAXN.
For each of the zed nodes, I have pub_resolution set to CUSTOM and pub_downscale_factor set to 2.0.
Temperature seems to be unrelated, as the failure occurs very soon after start (<= 1 or 2 minutes). I’ve noticed that jtop will spike to 100% usage intermittently, but it’s difficult for me to tell whether these are occurring when the failure happens. Additionally, both zed nodes may fail close to the same time and not just one, though this doesn’t seem guaranteed.
I monitor the jetson using jtop and its nvme using watch --interval 1 sudo nvme smart-log /dev/nvme0.
So far, there doesn’t seem to be a clear pattern when a zed node fails. Temperatures in jtop seem to be OK at around low 40s C, while the cpu cores hover around 30-40% utilization. Memory usage stays at about 6.7GB out of 15 The nvme temperature stays below 75C. GPU utilization will occasionally max out, but it’s not clear if this is correlating with a failure simply by visually observing jtop. Also, instantaneous power sometimes surges past 18W and even up to 20W. However, I have a voltage regulator (Pololu 12V, 15A Step-Down Voltage Regulator D24V150F12) capable of providing much higher continuous current. So I assume power brownouts are not an issue. Also, I assume brownouts would cause the entire board to fail/cycle power, which is not what I see.
When running the zed nodes, I’ve tried Depth mode set to PERFORMANCE for both as well as just one while having the other set to NONE. The behavior happens for both.
Also of note, I occasionally see on the orin:
[2024-05-21 20:59:27 UTC][ZED][WARNING] CAMERA NOT INITIALIZED in sl::ERROR_CODE sl::grab(sl::RuntimeParameters)
[ INFO] [1716325770.258925206]: Camera grab error: CAMERA NOT INITIALIZED [/robot/cameras/downward/zed_node:ZEDWrapperNodelet::device_poll_thread_func]
This error seems correspond with a dead zed node as the depth ros topic stops showing new frames when this error occurs. However, the zed node failure console statement in my previous post does not necessarily occur when this error occurs.
Also these corrupted frame messages very frequently (usually in bursts), also occur on the orin:
[Streaming] Warning: Corrupted frame chunk received (recv: 196 / expect 16100) from ip : 127.0.0.1 at ts 1716325158371(ms)
This message seem to be able can occur before and after a zed node dies and doesn’t seem correlated but still strange.
ZED SDK: 4.1.0 (installed from ZED_SDK_Tegra_L4T35.3_v4.1.0.zstd.run)
ZED X Driver: 0.6.4 (installed from stereolabs-zedx_0.6.4-MAX96712-L4T35.3.1_arm64.deb)